参考以下资料整理而成:
- http://www.zmonster.me/2018/11/10/sequence_to_sequence_learning.html
结论
- 模型对句子的主动与被动语态并不敏感,但是对输入词的顺序很敏感。
- 倒序输入句子能提升模型效果
DNN(Deep Neural Network, 传统的深度神经网络)
- Weakness
不能处理的输入和输出都是变长序列的问题,这种模型都能很好地进行处理
RNN(Recurrent Neural Network, 循环神经网络)
- Introduction
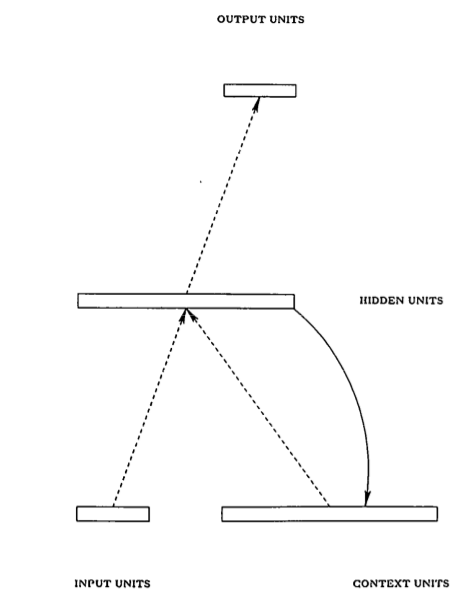
RNN 的隐藏层的一个环状结构能够缓存当前的输入,并用之参与下一次的计算,这样就隐式地将 时间信息 包含到模型中去了,在输入变长序列时,可以序列中的最小单元逐个输入。RNN 虽然在空间结构上可以很简单,但在进行训练时通常需要在 时间维度 上展开(unroll),所以可以认为它是一个在时间维度上的 DNN,于是 DNN 训练中会出现的 gradient vanish (梯度消失)也会出现,直观上可以将其理解为 “记忆的衰退”,换句话说, RNN 只能 “记住” 短期的信息。1997 年 “长短期记忆单元(Long Short-Term Memory, LSTM)” 被提出来解决这个问题,而本文提出的模型就是利用了 LSTM 的优点。
- Weakness
虽然能处理变长的输入序列,但得到的输出序列却是和输入序列长度一样的,限制仍然还在。
double RNN
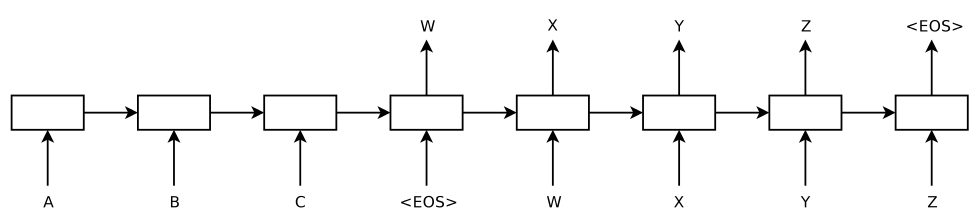
- Introduction
模型的左侧(到输入为 为止)是一个 RNN 在输入序列 “ABC” 上的展开,右侧是在输出序列 “wxyz” 上的展开,其中 是一个表示序列结束的特殊符号。功能上,第一个 RNN 用来将输入序列映射成一个固定长度的向量,这个 “固定长度的向量” 即是 RNN 中间隐藏层所缓存的对整个输入序列的 “记忆”,我们可以说它表示了输入序列的语义;然后用第二个 RNN ,来从这个向量中得到期望的输出序列。
除了这个特殊的模型结构之外,再就是用 LSTM 来保留 一定程度 的长期记忆信息,并且作者表示复杂的网络结构(更多的参数)具有更强的表达能力,因此每个 RNN 用的都是 4 层的 LSTM, 参数两多达 380M, 也就是 38 亿 —— Google 的朋友们你们真是站着说话不腰疼啊,38 亿参数的模型,一般人哪来这么多数据喂饱这个大胃王,哪来那么强劲的机器来训练。
beam search
- introduction
参考https://zhuanlan.zhihu.com/p/28048246 ,写的挺好的。
如下图用了一个slides的法语翻译为英文的例子,可以更容易理解上面的解释
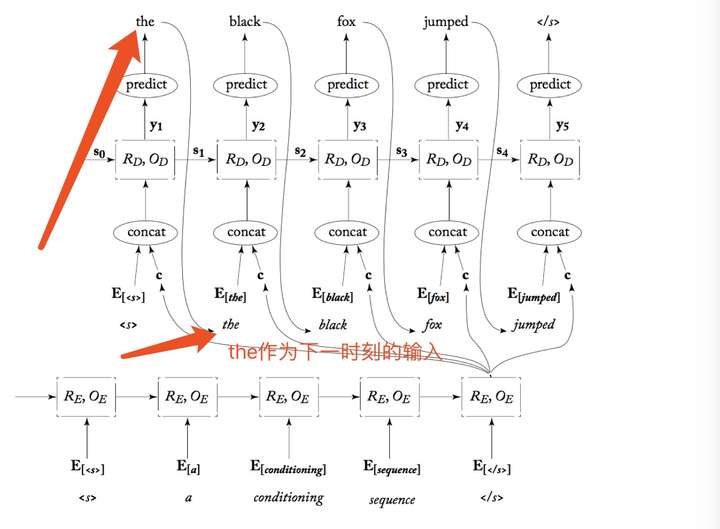
由于 “空白” 输出的存在,最后得到的非空白输出序列的长度就变成【可变】的了。语音识别和一些 OCR、手写识别是这么做的,效果也还不错。